
ViSQOL: an objective speech quality model
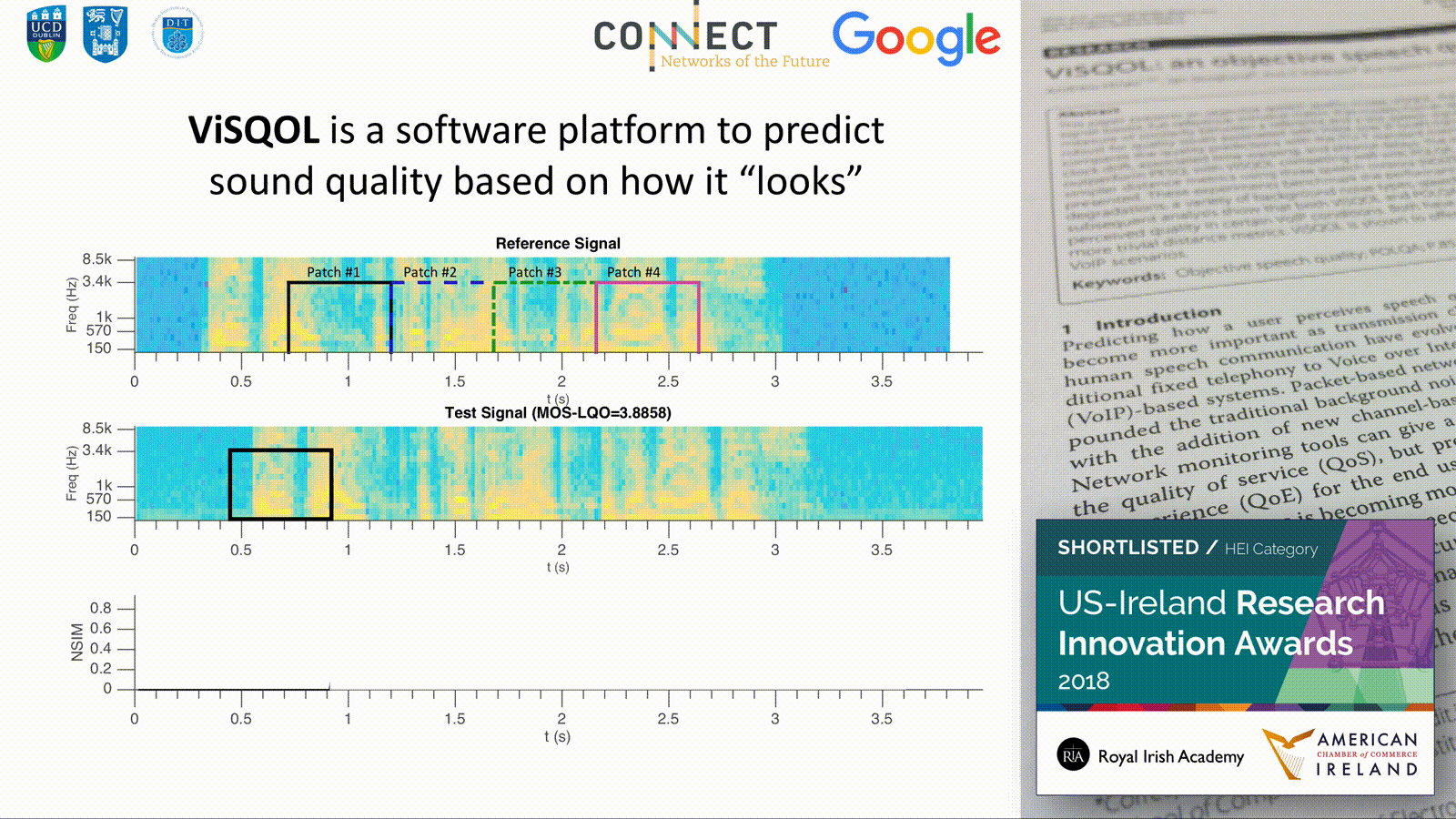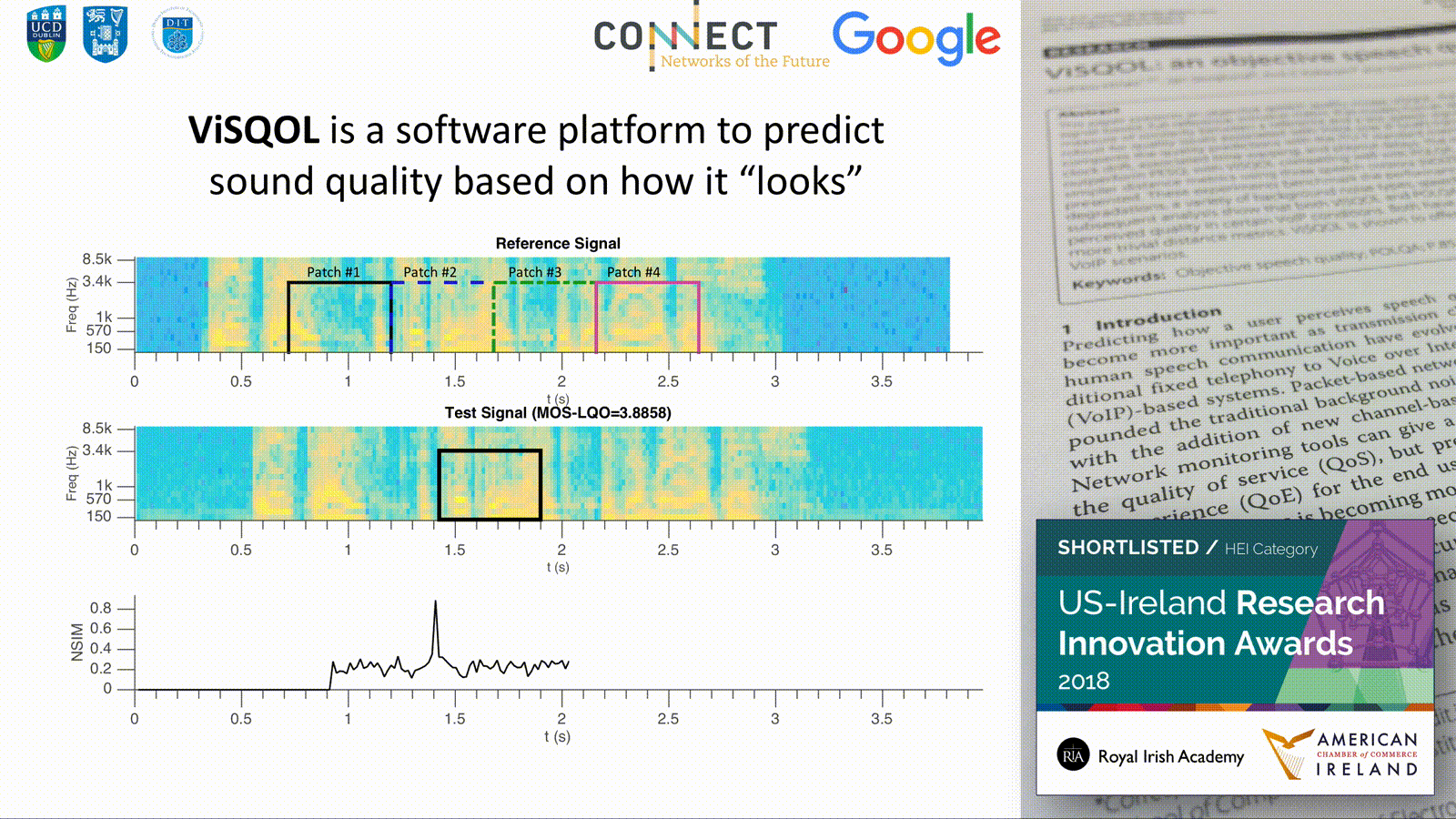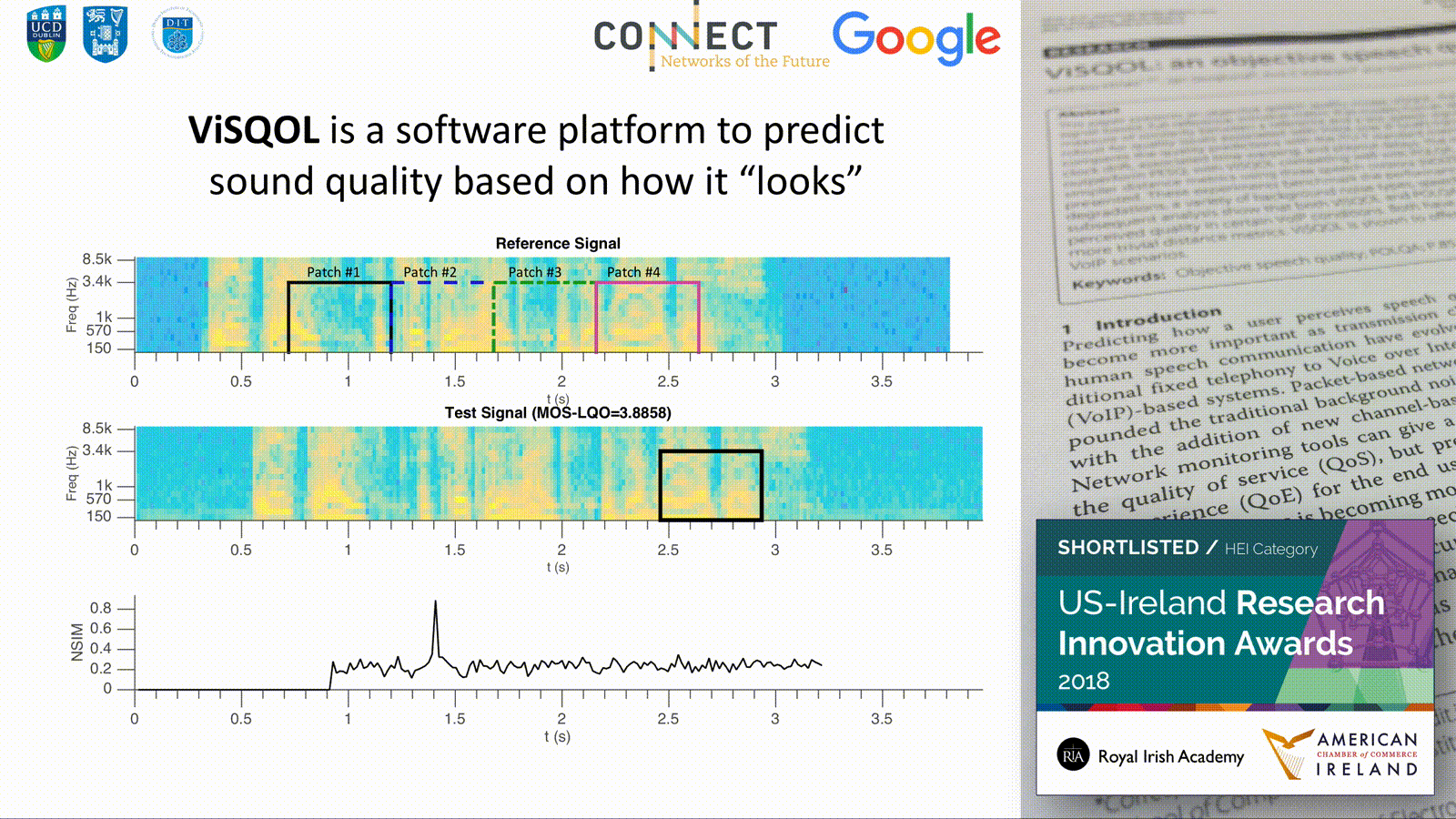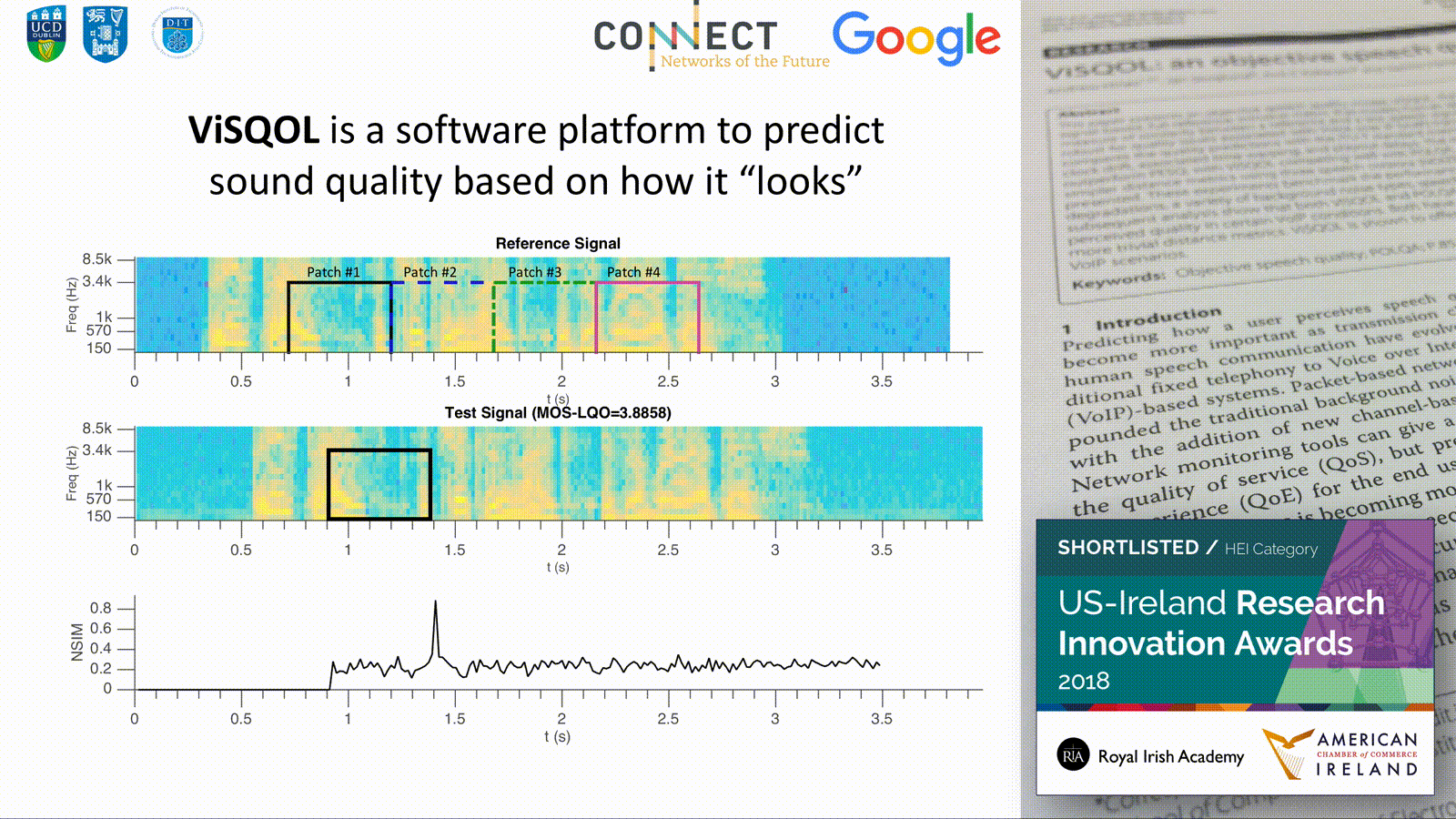
ViSQOL, the Virtual Speech Quality Objective Listener, is an objective speech quality model. It is a signal-based, full-reference, intrusive metric that models human speech quality perception using a spectro-temporal measure of similarity between a reference and a test speech signal. The metric has been particularly designed to be robust for quality issues associated with Voice over IP (VoIP) transmission. This paper describes the algorithm and compares the quality predictions with the ITU-T standard metrics PESQ and POLQA for common problems in VoIP: clock drift, associated time warping, and playout delays. The results indicate that ViSQOL and POLQA significantly outperform PESQ, with ViSQOL competing well with POLQA. An extensive benchmarking against PESQ, POLQA, and simpler distance metrics using three speech corpora (NOIZEUS and E4 and the ITU-T P.Sup. 23 database) is also presented. These experiments benchmark the performance for a wide range of quality impairments, including VoIP degradations, a variety of background noise types, speech enhancement methods, and SNR levels. The results and subsequent analysis show that both ViSQOL and POLQA have some performance weaknesses and under-predict perceived quality in certain VoIP conditions. Both have a wider application and robustness to conditions than PESQ or more trivial distance metrics. ViSQOL is shown to offer a useful alternative to POLQA in predicting speech quality in VoIP scenarios.
Please cite the following paper in any publications where you use the ViSQOL for Speech:
A. Hines, J.Skoglund, A.C. Kokaram, N. Harte. VISQOL: an objective speech quality model. EURASIP Journal on Audio, Speech, and Music Processing, 2015, 2015:13
Please cite the following paper in any publications where you use the ViSQOL for Audio and Music:
C. Sloan, N. Harte, D. Kelly, A. Kokaram, and A. Hines, “Objective assessment of perceptual audio quality using ViSQOLAudio,” Ieee transactions on broadcasting, 63 (4), p. 693–705, 2017.
A. Hines, P. Pocta, H. Melvin. Detailed Analysis of PESQ and VISQOL Behaviour in the Context of Playout Delay Adjustments Introduced by VOIP Jitter Buffer Algorithms. In Quality of Multimedia Experience (QoMEX), Fifth International Workshop on, Klagenfurt am Wo ̈rthersee, Austria, 2013.
A. Hines, J. Skoglund, A. Kokaram, N. Harte. Robustness of Speech Quality Metrics to Background Noise and Network Degradations: Comparing ViSQOL, PESQ AND POLQA. In IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 3697–3701, 2013.
A. Hines, E. Gillen, D. Kelly, J. Skoglund, A. Kokaram, N. Harte. ViSQOLAudio: An Objective Audio Quality Metric for Low Bitrate Codecs. J. Acoust. Soc. Am., 137 (6), pp. EL-449-EL455, June 2015
P. Pocta, H. Melvin, A. Hines. An Analysis of the Impact of Playout Delay Adjustments introduced by VoIP Jitter Buffers on Listening Speech Quality. Acta Acustica united with Acustica, 101(3):616–631, 2015
A. Hines, J. Skoglund, A. Kokaram, N. Harte. ViSQOL: The Virtual Speech Quality Objective Listener. In International Workshop on Acoustic Signal Enhancement (IWAENC), Aachen, Germany, 2012.